

pythonでseleniumを使ったスクレイピングについて説明する。
スクレイピングとはなんぞや、 seleniumってなんじゃ、という人は以下を参照されたし。

上記繰り返しになるが、スクレイピングを行う際は自己責任でどうぞ。
seleniumでのスクレイピングは、javascriptで動的に書き換わるページを対象にスクレイピングしたいときに効果を発揮する。
JavaScriptはブラウザ側で動作するため、直接HTMLファイルをダウンロードする方法(requests)ではJavaScriptが実行される前の値がとれてしまうが、seleniumはブラウザを操作するためのツールであるため、javascript実行後の値がとれるというわけだ。
使い方
さっそく使い方。requests編に続きyahooニュースの画面を開く。
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
UA = "あなたのブラウザのUA"
# ブラウザのオプションを格納する変数を取得
options = Options()
# UAの設定
options.add_argument("--user-agent=" + UA)
# options.add_argument('--headless') # Headlessモードを有効にする
# ブラウザを起動する
driver = webdriver.Chrome(options=options)
# URLをたたき画面を取得する
url = "https://news.yahoo.co.jp/"
driver.get(url)
# HTMLを文字コードをUTF-8に変換してから取得
html = driver.page_source.encode('utf-8')
# BeautifulSoupで解析
soup = BeautifulSoup(html, "html.parser")
# 主要ニュースの一覧を取得する
main_news = soup.find_all(href=re.compile("https://news.yahoo.co.jp/pickup/"))
print("title: \n")
for loop in main_news:
print(loop.getText())
# ウィンドウを閉じる
driver.quit()これを実行すると、ブラウザが立ち上がり、yahooニュースのトップ画面が開く。
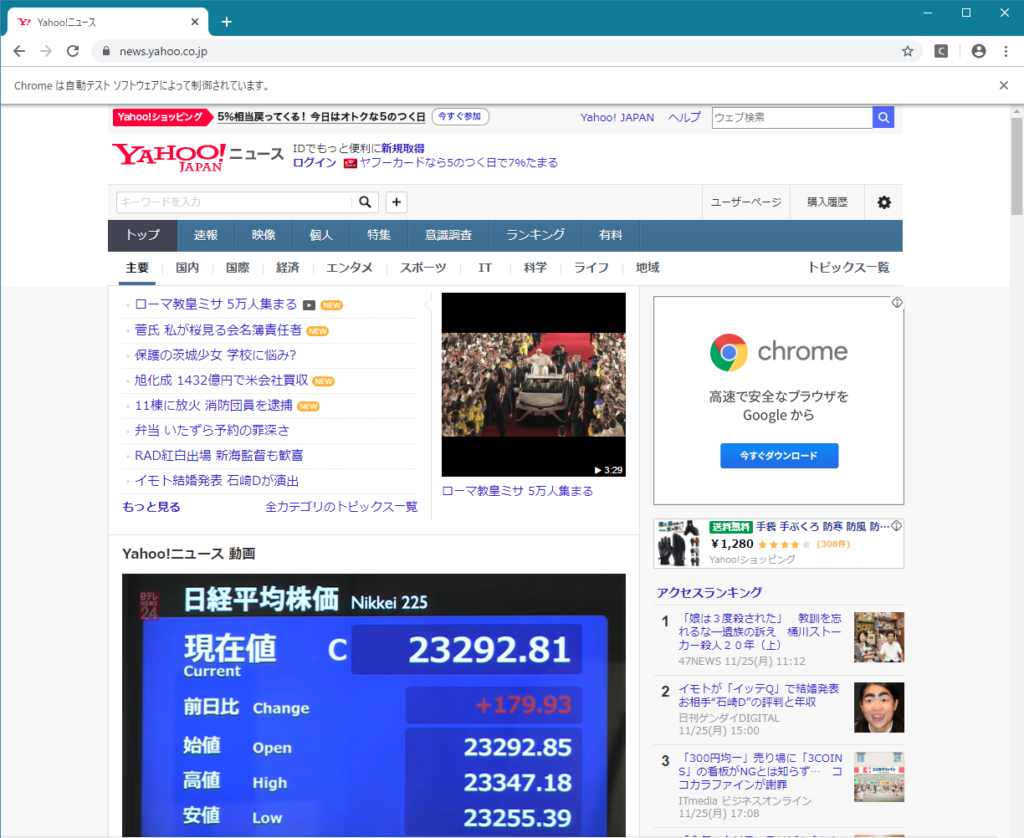
beautiful soupを使った値の取得結果がこちら。ちゃんと取れてる。
title:
ローマ教皇ミサ 5万人集まる
菅氏 私が桜見る会名簿責任者
保護の茨城少女 学校に悩み?
旭化成 1432億円で米会社買収
11棟に放火 消防団員を逮捕
弁当 いたずら予約の罪深さ
RAD紅白出場 新海監督も歓喜
イモト結婚発表 石崎Dが演出
3:29ローマ教皇ミサ 5万人集まる以下、適当な解説。
options.add_argument("--user-agent=" + UA)
# options.add_argument('--headless') # Headlessモードを有効にするoption.add_argumentでリクエスト時のオプションを追加できる。UAはなにもしないとpythonになるので、指定した方がいい。
ここでは実行時の挙動を確認するためにheadlessモードを無効にしているが、定期実行させたいときなどは毎回ブラウザ立ち上がってもうざったいので有効にするといい。
beautiful soupの簡単な使い方はこちらで説明。

コード内のコメントアウトでほぼ説明しきっているからあまり解説内容ないや、、、
おまけ
sleepをうまく使え
seleniumではブラウザを起動する分、requests編での説明したサーバとの接続時間に加えててブラウザの起動時間や画面描画時間がかかる。
処理を先に進めすぎると、javascriptの起動が間に合わず、意図した値が取得できないこともあるので注意が必要。
time.sleep関数をうまく使いたい。
その他のrequestsを比較したときのメリット
seleniumでブラウザを起動したあと、driver.getなどで画面取得をする操作は実際のユーザの操作に近しい。
サイトによってはリファラーのチェックをしていたり、chromeの開発者ツールを使ってもなかなかpostパラメータの解析が難しいことがある。そんなときは、seleniumを使えば大体一発でお悩みが解決する。


コメント